

What Is an AI Agent?
OpenClaw Academy · Part 1, Issue 01 · Concept post · Always free

Most definitions of an AI agent start with “an LLM that can use tools.” That’s accurate but useless. It doesn’t tell you why agents are hard to build correctly, why they fail in ways that chatbots don’t, or why the engineering discipline they require is genuinely different from anything you’ve built before.
Here’s the definition that actually helps:
An agent is a system that perceives inputs, maintains state, selects actions, executes them, and loops — without returning to the user between steps.
The last part is the one that changes everything.
The difference that matters: reactive vs agentic
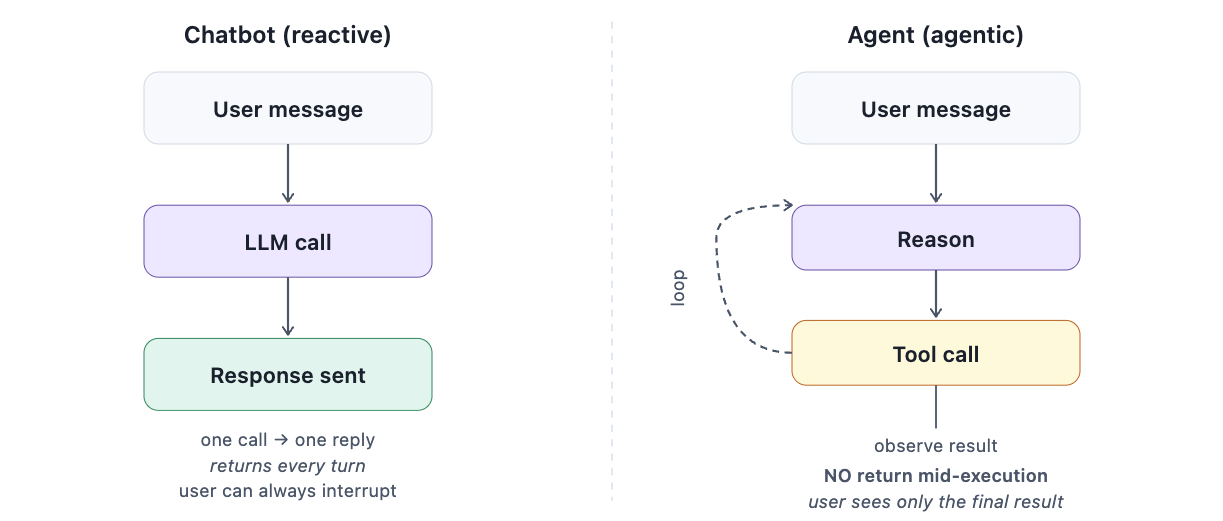
Chatbot returns after every message. Agent loops through tool calls before returning one response.
When you send a message to ChatGPT, it processes the message and returns a response. That’s it. The system is reactive: it waits for you, it responds, it waits again. There is no loop. There is no state that persists between your messages unless the interface explicitly stores and resends the conversation history.
When you send a message to an OpenClaw agent, something different happens. The agent receives the message, reasons about what to do, calls a tool (reads a file, queries an API, runs a command), observes the result, reasons again, calls another tool, observes again, and continues this loop until it decides the task is complete — before it sends you anything. The entire multi-step execution happens between your message and the response. You see only the result.
This is what “agentic” means architecturally. Not smarter. Not more capable. A different execution model. The loop runs autonomously. You’re not in it.
Why this changes the engineering discipline
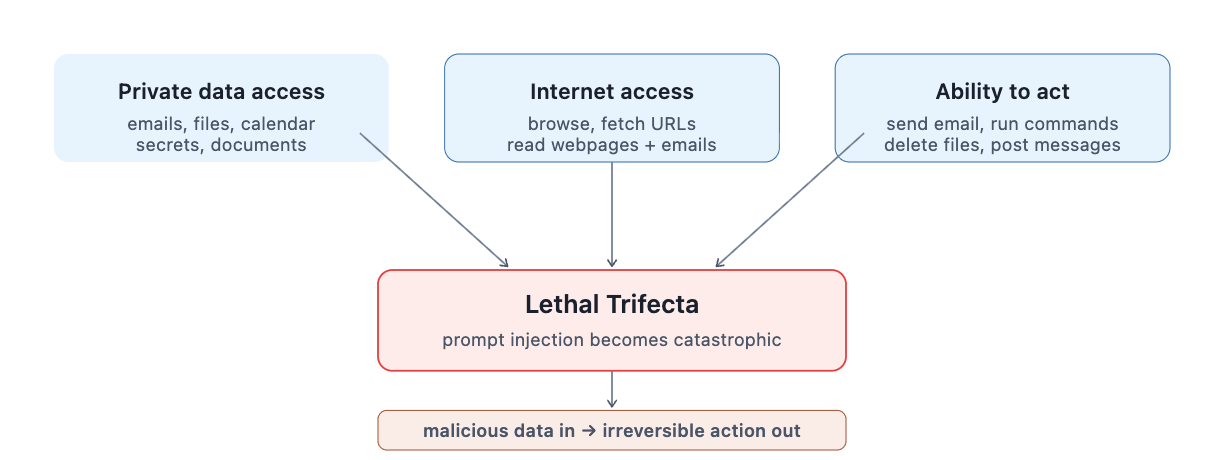
Figure 2 : The Lethal Trifecta — three conditions that together make prompt injection catastrophic for agents.
A chatbot that gives a wrong answer is annoying. A user reads it, notices it’s wrong, and asks a follow-up question. The feedback loop is fast. The cost of a mistake is low.
An agent that takes a wrong action is a different problem entirely. It read your emails, decided which ones were urgent, drafted replies, and sent three of them before you saw anything. Or it ran a cleanup script that deleted the files it decided were temporary. Or it booked a flight based on a calendar event it misread. By the time you see the result, the action has happened.
This is what security researcher Simon Willison calls the Lethal Trifecta: an agent with access to private data, access to the internet, and the ability to take action. When a system has all three, a single mistake — or a single malicious instruction injected into data the agent reads — can produce consequences that are difficult or impossible to reverse.
This isn’t a reason not to build agents. It’s a reason to build them with a different level of engineering discipline. The same discipline you apply to systems that touch money, or systems that touch production databases, or systems that send emails on behalf of users. The stakes are the same. The tooling is new.
OpenClaw is where that discipline gets learned most concretely. It’s the only production-grade open-source agent runtime with a real codebase, real CVEs (both publicly disclosed and patched), real supply chain incidents, and a live community stress-testing every assumption in public. There is no better laboratory for understanding what production agentic engineering actually requires.
The five things an agent needs
Every agent — in OpenClaw or any other framework — needs these five things to function:
Perception: How does the agent receive input? In OpenClaw this is the Channel Layer — Telegram, Discord, Slack, WhatsApp, iMessage. Each channel has a different protocol, different authentication method, and different failure mode. Telegram uses long-polling. Webhooks require a public IP. iMessage requires macOS. These aren’t cosmetic differences.
State: What does the agent know that persists between turns? In OpenClaw this is the Memory Layer — MEMORY.md, session files, and (with the Active Memory plugin) a vector retrieval system. An agent without well-designed state management either repeats work it’s already done or loses context it needs.
Reasoning: How does the agent decide what to do? In OpenClaw this is the Agent Runtime — the reasoning loop that constructs context from identity, skills, memory, and the incoming message, sends it to your LLM, and parses tool calls from the response.
Action: What can the agent actually do? In OpenClaw this is the combination of the Skills System (instruction sets that teach reasoning patterns) and the Tools Layer (exec, browser, MCP servers that provide capability). Skills and tools are not the same thing — Issue 04 covers why this distinction is the most important architectural decision you make when building with OpenClaw.
Evaluation: How do you know if the agent did the right thing? This is the piece that’s missing from almost every introduction to agentic AI, and it’s the piece that separates engineers who build demo agents from engineers who build production agents. Issue 07 covers it in full. For now: if you can’t measure whether an agent’s output was correct, you don’t have a production agent. You have a demo.
One action
Before Issue 02 on Thursday, do this one thing:
openclaw chat
Send a message that requires multiple steps. Something like: “Check my GitHub notifications and summarise anything that needs my attention.” Watch the terminal. You’ll see the agent call tools, observe results, reason about them, and call more tools — all before sending you a response. What you’re watching is the reasoning loop.
Notice that you can’t interrupt it mid-execution. Notice that the agent decides when the task is complete, not you.
That autonomy is the feature. It’s also the engineering challenge this newsletter is built around.
Three things to carry forward: 1. An agent is a loop, not a response. The execution happens before you see anything. 2. The Lethal Trifecta — private data + internet + action — means agents require the same engineering discipline as production systems with real consequences. 3. Evaluation is not optional. You need a way to measure whether the output was correct before you can call it production.
Issue 02 drops Thursday — the five-subsystem debugging map that makes every OpenClaw failure tractable. The GitHub vault asset for that issue (annotated openclaw.json + gateway-test.sh) is available to paid subscribers.
Subscribe free · Go paid ($15/month) · vault.systemdrd.com/openclaw-academy
Hey AI Engineering — "an agent is a system that perceives, maintains state, selects actions, executes them, and loops without returning to the user between steps" is the cleanest definition I've seen. Especially that last part — the autonomy between input and response is what makes it an agent and not just a chatbot with extra steps.
The lethal trifecta framing hits close to home. I build AI agents for businesses and scoping those three conditions — private data, internet access, action capability — is literally the first conversation.
Most clients come in wanting all three on day one and the job is slowing them down long enough to think about what happens when those three overlap without guardrails. "Your agent just emailed your entire client list a wrong price" is a conversation nobody wants to have twice.
The evaluation piece at the end is underrated. Everyone can demo an agent that looks incredible for five minutes. The gap between demo and production is where 90% of agent projects die quietly. Curious what evaluation frameworks you've seen actually work in practice versus the ones that look good on paper. Following this series.